
Healthcare organizations are drowning in data. From electronic health records and lab results to insurance claims and device feeds, the volume and complexity of health data are skyrocketing. In fact, healthcare now generates roughly 30% of the world’s data, and its data volume is growing faster than any other industry (projected 36% CAGR through 2025).
Yet more data doesn’t automatically mean better decisions—not when key information is trapped in silos, duplicated across systems, or riddled with errors. This is where AI in clinical data management comes in as a game-changer. AI can automatically cleanse, organize, and integrate data across the enterprise, transforming messy records into high-quality, usable data in real time. By combining artificial intelligence in clinical data management with modern standards like FHIR®, healthcare IT leaders can finally solve persistent data workflow challenges and unlock actionable insights across systems.
Healthcare generates ~30% of the world’s data, but value comes only when it’s standardized, deduplicated, and continuously validated — this is where healthcare data management ai solution makes the difference.
Why AI Is Needed in Healthcare Data Management
Data is the lifeblood of modern healthcare, but today’s enterprise data workflows are straining under legacy systems, silos, and poor data quality. In many hospitals and integrated delivery networks, patient information is spread across disconnected EHRs, billing systems, lab databases, and even paper files with little normalization. These inconsistencies and fragmentation create significant pain points where AI in hospital data management becomes essential:
- Incomplete or inconsistent records: When data isn’t standardized and consolidated, clinicians often lack a 360° view of the patient. Important details fall through the cracks. Fragmented, poor-quality data can hinder healthcare professionals’ ability to develop personalized treatment plans, monitor progress, and coordinate care effectively. Inaccurate or missing data can lead to misdiagnoses, treatment errors, and compromised patient safety. For example, if an allergy documented in one system isn’t visible in another, the consequences can be life-threatening.
- Duplicate data and patient mismatches: Identification errors are prevalent. The rate of duplicate patient records exceeds 20% in some health systems. These duplicates and overlaps aren’t just an IT annoyance; they account for nearly 2,000 preventable deaths and $1.7 billion in malpractice costs every year. Redundant records also lead to workflow inefficiencies (like repeat tests and administrative overhead) and revenue cycle problems (e.g., claim denials). Clearly, relying on manual data governance to catch every duplicate or error is untenable at enterprise scale, necessitating AI in healthcare administration to streamline operations.
- Labor-intensive data prep and integration: Healthcare executives know the headaches of healthcare data integration with AI when dealing with legacy formats. Data from older EHRs or departmental systems often must be painstakingly mapped and cleaned before it’s analytic-ready. Interfaces break, columns don’t align, and IT teams spend countless hours on extract-transform-load (ETL) routines. In a fast-paced environment, these delays mean lost opportunities for timely decisions.
The impact of these challenges is felt across the organization: operational inefficiencies, frustrated staff, suboptimal clinical decisions, and hindered innovation. AI in clinical data management is needed in health data management because it directly addresses these pain points through intelligent automation and continuous learning.
Use Cases for AI in Data Management

How exactly can AI in health data management relieve the day-to-day data headaches in a healthcare enterprise? Below, we highlight a few high-impact use cases. These are practical applications where a comprehensive healthcare data management AI solution is already proving its value:
Automated Deduplication & Entity Resolution
Duplicate records and inconsistent entries plague hospital databases. In healthcare, duplicate patient files can lead to serious safety and financial issues. AI-powered data matching is a powerful solution: machine learning models analyze variations and similarities across records to determine if they refer to the same person or entity.
For example, an AI can recognize that “John Smith” and “Jonathan Smith, Jr.” might be the same patient even if a birthdate or address differs slightly. It can then merge or link these entries, reducing fragmentation. This not only improves reporting accuracy but also prevents clinical mistakes caused by scattered histories. In one national project, our team deployed an ML-based duplicate identification model to consolidate patient records, significantly cleaning up the registry.
AI-driven deduplication saves countless hours of manual cleanup and ensures that everyone from clinicians to analytics teams is working with a single, golden record.
NLP for Unstructured EHR Notes
A huge proportion of clinical information lives in unstructured text: physician notes, discharge summaries, operative reports, or referral letters. Estimates suggest about 80% of healthcare data is unstructured text or images, which traditional systems can’t readily use.
AI in clinical data management changes via natural language processing (NLP). NLP algorithms can read free-text documents and extract structured data points (problems, medications, lab values, etc.) or even generate summaries. For instance, an NLP model could parse a doctor’s narrative clinic note and pull out the patient’s chief complaint, current medications, and key vitals, then populate those into discrete EHR fields automatically.
This not only saves clinicians documentation time, but also makes that information searchable and usable for clinical analytics. Large language models (LLMs) have shown remarkable ability to interpret clinical text; when harnessed carefully (ideally with private-hosted models for privacy), they can flag if a SOAP note is missing a section or suggest adding relevant details from other records. In practice, hospitals are already using NLP to mine insights from years of archived notes; one study notes that integrating unstructured notes into data models enhances patient profiles and improves analytics. Artificial intelligence in clinical data management thus unlocks value from texts that were previously unused data.

Predictive Analytics for Anomalies & Compliance
Another use of healthcare data management with AI is to continuously monitor data streams for unusual patterns, effectively an early warning system for both clinical and operational anomalies. On the clinical side, this could mean analyzing patient data in real time to catch out-of-range values or combinations that signal risk. From a data management perspective, AI-based systems can also perform continuous data auditing.
They will flag data that violates expected rules or trends, for instance, if a batch of lab results comes in with units missing or if a day’s worth of billing claims show an abnormal spike in one procedure code (indicating a possible coding error or fraud). Unlike static rules, AI learns what “normal” looks like in complex, high-dimensional data, so it can catch subtle anomalies.
This kind of intelligent automation accelerates workflows and keeps data internally compliant with rules before it ever causes a problem. By proactively detecting errors and inconsistencies, AI in clinical data management helps maintain a high standard of data quality behind the scenes.
AI-Driven Benefits Across the Data Lifecycle
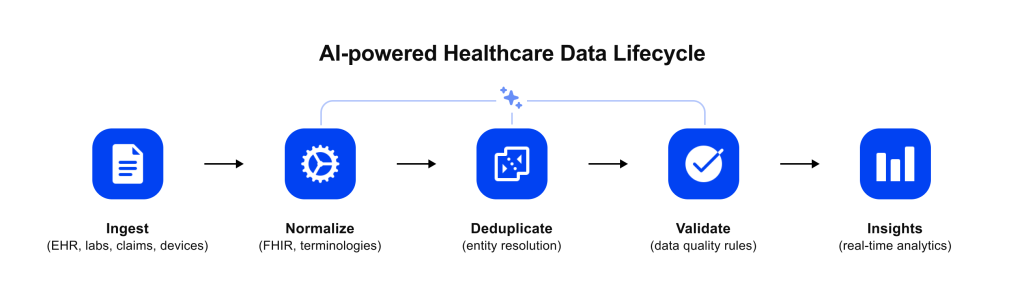
When implemented strategically, AI enhances healthcare data management from end to end. Let’s break down some of the key benefits that AI brings at each stage of the data lifecycle:
- Accelerated ingestion and transformation: AI can dramatically speed up the intake of data from various sources and the conversion of that raw data into usable formats. Rather than writing one-off scripts for each new data feed, organizations can use AI-driven mapping and normalization. For example, machine learning models learn to map legacy data fields to standard ones (like mapping dozens of old lab code variations to standard LOINC codes). This means onboarding a new data source or partner interface goes from a multi-week IT project to a near-automatic process. Streaming data pipelines augmented with AI also allow real-time or more frequent updates instead of batch delays. The net effect is faster data availability: clinicians and analysts get the data they need promptly, which can be critical for time-sensitive decisions (e.g., emergency care, outbreak monitoring).
- Continuous data quality monitoring: Data quality is not a one-and-done task; it requires ongoing oversight. AI in hospital data management excels at this continuous data governance role. An AI “data steward” can constantly scan incoming data for errors, missing values, or outliers, and either fix issues or alert staff in real time. Did a vital sign value slip in that’s an improbable outlier? (say, a heart rate of 500 bpm due to a typo.) The AI can catch it instantly. Are certain required fields frequently left blank by a particular department’s system? The AI can identify that pattern and notify the data governance team to investigate or enforce compliance. This level of 24/7 automated quality control is virtually impossible to achieve with manual checks alone.
By integrating AI into healthcare data governance, organizations ensure that their information remains accurate, consistent, and trustworthy over time.
- Real-time insights and decision support: Traditional reporting often lags behind events—weekly or monthly reports find problems after the fact. AI flips this script by enabling real-time data insights in healthcare operations. AI in healthcare administration allows advanced analytics models (especially those employing machine learning) to analyze live data streams to detect emerging trends or to predict outcomes before they happen.
By delivering the right insight to the right person at the right time, AI-enabled data management helps healthcare organizations become more proactive and data-driven.
- Improved compliance and traceability: In highly regulated environments like healthcare, data governance and compliance are paramount. AI can support this, if deployed correctly, by helping ensure that data workflows are audit-ready and aligned with rules (HIPAA, GDPR, internal policies, etc.). For example, AI-driven monitoring can analyze access logs to flag unusual data access patterns that might indicate a privacy breach or recommend stricter role definitions when it detects systematic over-exposure of PHI. It can also help maintain detailed logs and “audit trails” of data processing activities by recording when, how, and on what basis an AI component transformed or moved data, making later audits and root-cause analysis easier than with manual documentation alone.
AI tooling can also assist with data retention and deletion policies—classifying records that should be archived or purged according to governance rules and triggering those actions through existing data platforms—and validate outgoing data against standards before it is exchanged with external partners, supporting HIPAA-compliant data sharing and reducing interoperability and reporting errors.
At the same time, AI itself is another regulated data processor: models must be deployed in compliant environments (e.g., private or isolated LLMs, not public models that reuse data), integrated with proper access control, logging, and risk assessment.
FHIR + AI: A Perfect Match
To maximize AI’s impact on healthcare data, a solid data architecture is essential. This is why we advocate pairing AI initiatives with a FHIR-based infrastructure. FHIR (Fast Healthcare Interoperability Resources) is a modern standard (developed by HL7) for structuring and exchanging health data via web APIs.

Essentially, FHIR defines a consistent format for health data “entities” (Patient, Observation, Medication, etc.) and how to retrieve/update them (RESTful APIs). Marrying artificial intelligence in healthcare data management with FHIR brings several advantages:
- Easier data integration for AI: FHIR provides a common language for disparate systems. Instead of wrestling with dozens of proprietary data formats, an AI system can pull data from multiple sources that all speak FHIR. This dramatically simplifies healthcare data integration with AI tools.
For example, if an AI model needs patient demographic info, medication lists, and lab results, FHIR’s standardized resources allow those to be fetched in a uniform way (often in JSON format). The AI doesn’t have to include custom parsers for each source; it can consume FHIR data directly. This means less time spent on data preparation and more time generating insights.
- Improved data quality and consistency: By design, a FHIR-based system enforces structured data and standard code systems. Every piece of data is categorized (as a FHIR resource type) and uses defined fields. This structure inherently promotes data quality: required fields can be validated, coded values (like ICD-10 diagnosis codes or SNOMED concepts) ensure semantic consistency, and so on.
For AI algorithms, good data quality is gold. High-quality, standardized data means models train better and produce more reliable outputs. As noted in another of our articles on preparing clinical data for AI, adopting FHIR from the start “simplifies training AI models” and “reduces preprocessing time.” FHIR gives you cleaner inputs, so your AI isn’t learning from noise or spending 80% of its time cleaning data.
- Interoperability and scalability: AI in hospital data management often needs to operate across multiple systems and organizations—think of an AI that aggregates data from primary care, specialty clinics, pharmacies, and wearable devices. FHIR’s interoperability makes this feasible. Because it’s widely adopted, many EHRs and health IT products now offer FHIR APIs.
This means your AI-powered application can query data from various sources without custom one-off integrations for each. It also means that the outputs of your AI (predictions, alerts, recommended actions) can be packaged as FHIR resources and fed back into clinical workflows.
This flexibility is crucial for scaling AI solutions beyond a pilot project: as you expand to new partners or regions, FHIR provides a common ground.
- Compliance and governance alignment: Another reason FHIR and AI pair well is that FHIR inherently supports data governance needs. The standard includes built-in fields for provenance, audit logs, and access control tags, which help maintain compliance. If your data platform is FHIR-based, it’s easier to ensure that AI outputs are traceable and transparent (you can point to the exact input resources that led to an AI’s prediction, for instance).
Additionally, many regulations (like the U.S. ONC certification criteria) increasingly expect the use of FHIR. By using FHIR, you’re future-proofing your architecture against regulatory changes. It helps that FHIR was designed with modern security (OAuth2, etc.) and privacy in mind, so building your AI on a FHIR foundation makes it simpler to meet HIPAA and GDPR requirements for data handling.
Need a FHIR-first data layer for AI?
From mapping and validation to scalable APIs and terminology services —
Edenlab helps modernize legacy environments with HL7 FHIR.At Edenlab, we’ve invested heavily in this FHIR-first approach to AI-ready infrastructure. Our Kodjin FHIR Server is a prime example. It’s a FHIR-centric data platform that serves as a high-performance repository and API layer for healthcare data. By deploying Kodjin, organizations get a single source of truth where all data is stored as FHIR resources (with strict validation).
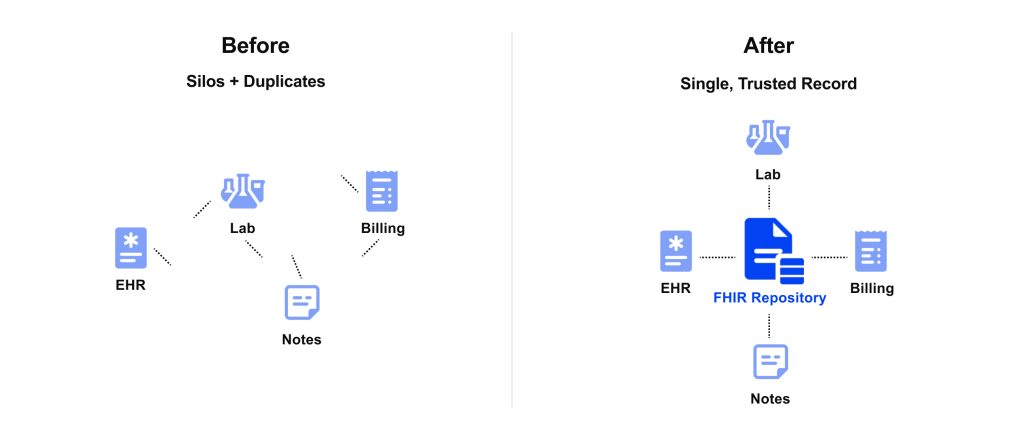
This means any application or AI model tapping into the data sees a consistent, standardized view of the information. Kodjin handles the heavy lifting of data mapping, terminology normalization, and patient identity resolution, so your AI doesn’t have to. It’s also built for real-time processing (using an event-driven microservices architecture) to support on-the-fly AI analyses as data streams in. By using Kodjin or similar FHIR-based solutions, you essentially make your data “AI-ready” by default. The AI can plug in, trust the data quality, and focus on generating value (rather than on cleaning or reconciling inputs).
Conclusion
Healthcare organizations are facing both unprecedented growth in data and rapid advances in AI. Artificial intelligence in clinical data management can turn this growing volume of information from a liability into a strategic asset by automating core tasks such as cleaning, deduplication, validation, and integration, while supporting downstream workflows like AI prior authorization. This frees teams to focus on higher-value work while enabling more accurate analytics, faster decision-making, and real-time data insights.
However, the full value of AI is only realized when it is built on a strong data foundation. Aligning AI with a FHIR-based, interoperable architecture ensures consistency, scalability, and regulatory trust.
The result is a healthcare data management AI solution that is more efficient, accurate, and connected, where better data directly supports better care, streamlined operations, and continuous innovation.

We dive deep where others skim
Want cleaner data and faster insights? Tell us what systems you have (EHR, claims, labs, devices), and we’ll propose an AI + FHIR approach for data quality, governance, and interoperability.
FAQs
Is AI in data management compliant with HIPAA/GDPR?
It can be compliant, but compliance depends on whether and how the AI processes patient data. First, confirm if the AI touches PHI/PII at all; if it does, the system must follow HIPAA/GDPR requirements for access control, logging, encryption, retention, and vendor agreements.
Next, validate the AI deployment model: avoid sending raw patient data to public LLMs; use private/isolated models or tightly controlled cloud deployments, and apply de-identification/pseudonymization when patient data must be used for NLP/LLM tasks (and treat re-identification risk as part of the assessment).
Finally, align governance with modern AI expectations (e.g., transparent model documentation and risk controls under ONC HTI-1, where relevant, and EU AI Act risk-based obligations for high-risk healthcare AI) and ensure baseline security principles are consistently applied end-to-end (least privilege, segmentation, audit trails, incident response).
What’s the roadmap for AI adoption across enterprise health systems?
A practical roadmap usually starts with foundation work (data inventory, target architecture, security/governance, and a standard model like FHIR), then moves to “quality-first” quick wins (deduplication, normalization, automated validation, anomaly detection) that improve trust in the data.
Next comes operationalization (data pipelines with monitoring, human-in-the-loop workflows, model lifecycle management, and auditability), followed by expansion to unstructured data (NLP for notes) and more advanced cross-domain use cases (real-time decision support, population analytics, and workflow automation).
Mature programs then scale across sites and partners with repeatable onboarding patterns, shared terminology services, and standardized controls for privacy, compliance, and model updates.
What are the typical costs and ROI of AI-powered data management?
Costs typically fall into a few buckets: platform/infrastructure (compute, storage, pipeline tooling), integration (mapping, connectors, FHIR enablement), governance/security (logging, access controls, audits), and ongoing operations (monitoring, model updates, data stewardship).
ROI usually comes from measurable reductions in manual data prep, faster onboarding of new sources, fewer duplicate records and matching errors, fewer downstream reporting and claims issues, and improved staff productivity—plus avoided risk from better compliance and fewer data-quality-driven clinical/operational incidents.
Most organizations justify it by tying outcomes to specific KPIs (duplicate rate, data quality rule pass rate, time-to-ingest, analyst hours saved, incident volume) rather than generic “AI value.”
Stay in touch
Subscribe to get insights from FHIR experts, new case studies, articles and announcements
Great!
Our team we’ll be glad to share our expertise with you via email







