
LLMs can genuinely help in healthcare, speeding documentation, turning long guidelines into usable briefs, and accelerating internal analysis. The primary threat to protected health information (PHI) isn’t “LLMs in general” but sending identifiers to public, multi-tenant models such as ChatGPT, Gemini, or Claude, where retention, training, and geography may sit outside your control.
When you need hosted controls, consider Azure OpenAI for tenant-scoped, in-region processing with “no training on your data” and still apply de-identification and minimum-necessary prompts.
The safer pattern is to run models in an isolated environment under your policies, with least-privilege access and clear data boundaries; the first question isn’t which model, but what the model is allowed to see. Many high-value use cases run on semantic metadata, codes, aggregates, and task-scoped context, so PHI never leaves your perimeter.
At the same time, LLMs introduce risks traditional programs miss: prompt and log leakage, unclear retention, weak provenance, and opaque reasoning. You need governance that shows how data flows end-to-end, who accessed what and when, and why an output is trustworthy, aligned with HIPAA’s privacy/security rules and newer guardrails like HTI-1’s algorithm transparency and the EU AI Act’s risk-management requirements.
This article is useful for providers and health information exchange (HIE) operators navigating common HIE challenges and business-minded decision-makers for data governance, risk, and vendor selection who must validate solutions and prove healthcare data compliance without wading into low-level engineering.
We’ll explain how to make AI HIPAA compliant, clarify the real risks, help you choose between public and isolated models, and show how to achieve HIPAA compliance in AI.
Highlights:
- Compliance depends on deployment and data exposure. Isolate models for PHI and use public models only for non-PHI with safeguards.
- A metadata-first design keeps PHI inside your boundary. Models work on codes, aggregates, and task-scoped context.
- Assess risk through access, egress, and impact. Increase human review and auditability as risk grows.
Why Healthcare Organizations Are Turning to LLMs
Budgets are tight, worklists keep growing, and stakeholders expect faster, safer service. HIPAA-compliant AI helps teams remove manual steps, shorten cycle times, and turn scattered information into decisions when deployed with clear guardrails and a privacy-first architecture. Let’s look at some benefits that hospitals receive from implementing HIPAA-compliant LLMs.
- Efficiency and automation. Draft clinical notes from structured inputs and templates to cut clicks and rework, summarize long guidelines and medical texts into concise briefs clinicians can verify, and remove manual steps across intake, discharge, and back-office tasks to shorten cycle times without adding burden.
- Earlier detection and population insights. Analyze de-identified, aggregated data to support healthcare risk analytics, surface risk signals, care gaps, and utilization trends, route flagged items with rationale and source links to the right team, and give quality and population health programs timely, auditable cues without exposing individual records. See our guide on the AI clinical data review process.
- Patient-facing support (non-PHI). Answer coverage and benefits questions consistently across web, mobile, and interactive voice response (IVR), manage scheduling, directions, and prep instructions with guardrails that keep PHI out of prompts by design, and raise first-contact resolution while lowering hand-offs and wait times.
- Internal processes. Accelerate compliance reporting with first drafts and policy lookups anchored to internal standards, suggest codes and modifiers for human confirmation to reduce avoidable denials, and speed research with literature reviews, evidence maps, and structured summaries ready for downstream analysis.
- Strategic drivers. Improve the patient experience with faster answers and more precise instructions at each step of care, reduce operating costs by automating repetitive work and shrinking time-to-decision across clinical and administrative workflows, and enable safe innovation through privacy-first architectures and traceable outputs.
Beyond HIPAA: The Regulations That Define Safe AI Operation
HIPAA sets the baseline for privacy and security of protected health information. Teams worry about LLMs because prompts, logs, and embeddings can capture identifiers, vendors may retain inputs, and cross-border processing can complicate Business Associate Agreements (BAAs) and data residency.
BAAs are HIPAA-mandated contracts between a covered entity and any vendor that handles PHI. They define permitted uses/disclosures, required safeguards, breach-notification duties, and subcontractor flow-down terms. HIPAA expects minimum-necessary access and auditable controls, but it doesn’t spell out how AI should behave inside clinical workflows.
Yet, HIPAA isn’t the only guide. That’s where newer frameworks step in: the U.S. Health Data, Technology, and Interoperability: Certification Program Updates, Algorithm Transparency, and Information Sharing (HTI-1) rule and the European Union’s Artificial Intelligence Act (EU AI Act) explain, in practical terms, how models must operate safely day to day.
HTI-1 (U.S.)
HTI-1 is ONC’s 2024 final rule that updates the Health IT Certification Program and replaces legacy CDS with Decision Support Interventions (DSI). For AI used inside certified electronic health record (EHR) workflows, it requires algorithm transparency via plain-language source attributes (what data the model uses, how it was built and evaluated, performance, and limits) and ongoing intervention risk management.
Certified health IT developers have been required to support these transparency fields since January 1, 2025, with ongoing maintenance commencing on January 1, 2025. In short, HTI-1 complements HIPAA rules for LLMs and PHI by adding AI-specific duties, explaining the model, managing its risks, and keeping the disclosures current.
EU AI Act (EU)
The EU AI Act is a risk-based law that tells you how AI must run safely. Most clinical deployments will fall into high-risk and must implement an end-to-end risk-management system, strong data governance for training/validation/testing, detailed technical documentation, automatic logging, clear instructions to deployers, explicit human oversight, and measurable accuracy, robustness, and cybersecurity. The Act’s final text was published in the Official Journal in July 2024 and creates forward-looking obligations that sit alongside HIPAA’s privacy and security rules.
Deployment & Data Exposure: The Compliance Lever
Choosing where an LLM runs and what it can see is your biggest privacy decision. Our default recommendation is simple: for anything that could touch PHI, deploy an isolated model and keep raw data inside your boundary. Public, multi-tenant LLMs are not recommended for healthcare workloads; even if you’re going to use them for strictly non-PHI tasks, they must be wrapped in strict safeguards.
Isolated/specialized or custom LLMs
Use an isolated deployment whenever patient context is in scope or outputs can write back to clinical systems. Run on a HIPAA-eligible cloud with a signed BAA, private networking, strict egress controls, encryption, granular Role-Based Access Control (RBAC) and Attribute-Based Access Control (ABAC), immutable audit logs, and human-in-the-loop review for patient-impacting outputs. Keep raw PHI inside your own systems and expose only governed semantic metadata such as codes, aggregates, and task-scoped features.
Hybrid
If your portfolio spans both knowledge tasks and PHI workflows, use a broker/policy proxy to classify each request, strip or replace identifiers, and route it to the appropriate model. Retrieval-augmented generation (RAG) should serve only vetted snippets or metadata, while the proxy enforces minimum-necessary access, logs the full chain, and blocks risky egress.
Public LLMs
Public LLMs are not recommended for healthcare data, but they deliver strong writing and reasoning quality thanks to training at scale and frequent updates. Use them only for non-PHI tasks, such as literature and guideline summaries from public sources, internal policy, standard operating procedure (SOP) drafting, engineering assistance, and patient FAQs about coverage and scheduling.
Another option is Azure OpenAI, which provides enterprise-grade access to ChatGPT within Microsoft’s secure cloud environment. Unlike public LLMs, Azure OpenAI runs in an isolated tenant, ensuring that prompts and outputs stay within your organization’s Azure boundary. Data is not used for model training, and processing occurs in the selected regional datacenter. Yet, you still need to treat PHI carefully, applying de-identification, minimum-necessary prompts, short retention, and immutable logging.
To avoid PHI risks in AI and LLM adoption, apply de-identification before any prompt or embedding by removing direct and quasi-identifiers, using stable pseudonyms, shifting or bucketing dates, generalizing locations, and aggregating rare attributes. Enforce a policy proxy that prefilters to minimum-necessary semantic metadata, blocks risky egress, and logs immutably; restrict access with role- and attribute-based controls with MFA, set short retention with verifiable deletion, require vendor “no training on your data” and regional processing, and keep this usage narrowly scoped and regularly reviewed.
Our own product, Kodjin Analytics, is a secure AI foundation that lets you bring your own LLM and run it with uniform guardrails. PHI stays inside your boundary while models see only governed semantic metadata, and a policy proxy enforces minimum necessary access, encryption, egress controls, and immutable logs.
Retrieval-Augmented Generation is policy-controlled, so the model uses only vetted sources and de-identified snippets. Retention is configurable with a clear time to live and verifiable deletion across systems. You can deploy in an isolated cloud environment under BAA and keep full traceability for audits.

Classifying LLM Use with PHI: Low, Medium, and High Risk
In healthcare, a clear way to place an LLM is to weigh access, egress, and impact: what the agent can see, what (if anything) leaves your boundary, and whether its output could influence care or billing.
As a rule, avoid public LLMs for any workload that involves PHI. Use a metadata-first design so raw PHI stays inside your perimeter while the model works only with semantic context (codes, aggregates, task-scoped facts). Viewed through this lens, the safest wins sit at the low-risk end, work that never includes PHI in prompts and delivers quick efficiency gains.
Low risk. These are workflows where PHI never enters the prompt. Administrative tasks, benefits FAQs, intake routing, and scheduling are safe because identifiers are excluded by design. Literature and guideline summarization stays low risk when it relies on public sources or fully de-identified materials, producing concise briefs that clinicians can verify.
Population insights fit here when analytics run on de-identified or aggregated data and return codes, counts, or ranges instead of patient data. Content generation also belongs here when you standardize letters and instructions using synthetic examples. Developer or analyst assistance is similarly low risk when it runs in a sandbox without connectivity to clinical systems.
Medium risk. These scenarios are workable with tight guardrails. You can extract entities or summarize exported notes if robust de-identification is applied, prompts are trimmed to the minimum necessary, and humans review outputs before use.
Retrieval-augmented generation over internal knowledge is acceptable when the retrieval layer serves only semantic metadata, blocks attachments and direct identifiers, and logs every query and snippet. AI-powered prior authorization and coding assistance can also sit here when the agent consumes structured fields and codes rather than free text, writes back a draft for human confirmation, and leaves a complete audit trail.
High risk. These require isolation or a redesign. Pasting notes, images, or recordings into prompts risks disclosure; de-identify via a policy proxy first. Patient-level CDS with PHI must run on isolated, HIPAA-eligible infrastructure. Include human-in-the-loop review and end-to-end traceability.
Training on sensitive data demands de-identification, governance, and a signed BAA. Skipping them risks lasting exposure in model weights and vendor logs. Direct use of a public LLM against EHR/HIE APIs breaks the minimum-necessary rule and introduces retention and reuse risks you cannot control.
Designing a data analytics platform from the ground up?
We are here to help. Check our
Healthcare analytics product development servicesWhat to Check Before Selecting or Building an LLM Solution
Run a quick buy-vs-build screen before committing a budget or signing with a HIPAA-compliant AI partner. Ensure any product or planned stack satisfies day-one contractual, security, audit, and regulatory requirements. Use the checklists below to request concrete artifacts.
Vendor due diligence for commercial AI HIPAA-compliant technology
- Data use limits. Require “no training on your data,” tenant isolation, a full subprocessor list, model provenance, and regional processing controls.
- Security controls. Encryption in transit/at rest (prefer customer-managed keys), granular RBAC/ABAC with multi-factor authentication (MFA), network isolation, and documented vulnerability management.
- Auditability. Exportable, immutable logs that capture user, scopes, inputs, outputs, and data sources, plus the ability to reconstruct any interaction end to end.
- Retention/deletion. Clear time-to-live (TTL) for prompts, outputs, and embeddings, with evidence of purge across primary systems and vendor logs.
- Policy enforcement. Availability of a policy proxy or prompt firewall to enforce minimum-necessary access, redact/tokenize sensitive strings, and block risky egress.
- Regulatory posture. Readiness for HTI-1 transparency (DSI “source attributes,” intervention risk management) and, if relevant, EU AI Act obligations (logging, human oversight).
- Operational readiness. Current SOC 2/ISO 27001, recent pen tests, commit to incident Service Level Agreements (SLAs), define Recovery Time Objective (RTO) and Recovery Point Objective (RPO) targets, capacity limits, and performance SLAs.
- Use-case fit. Confirm the product is intended for non-PHI or fully de-identified workloads if it is multi-tenant or public.
Building a custom HIPAA-compliant LLM
- Isolated deployment
- Metadata-first pipeline
- Observability & trust
- Safety checks
- Lifecycle
- Governance
- Trade-off.
Best Practices for Commercial AI HIPAA Compliance
Once you decide to adopt or build custom HIPAA-compliant AI solutions, turn intent into controls. The goal is simple: avoid risks of AI in healthcare compliance, protect PHI by design, prove it with evidence, and keep models useful without opening your perimeter.
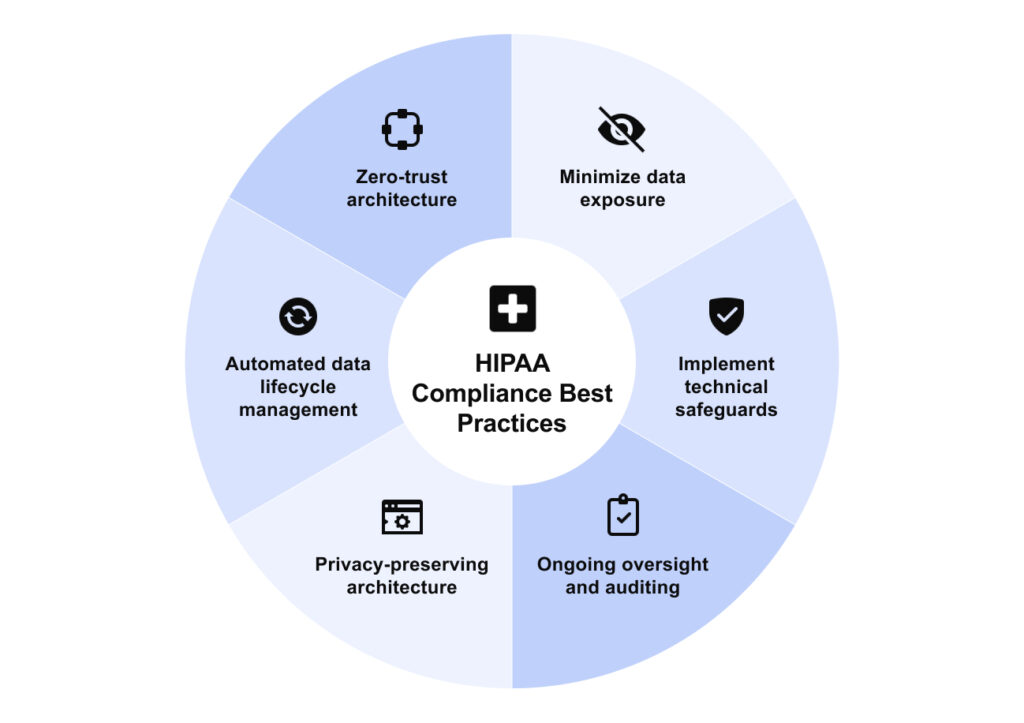
Minimize data exposure
Default to de-identification or pseudonymization, and apply the minimum necessary principle to every request and response. Keep raw PHI inside your boundary and give the model only semantic context (codes, aggregates, task-scoped facts). Avoid putting PHI into prompts unless there is a documented need and a compensating control. Prefilter and aggregate inputs, tokenize or mask sensitive strings in transit, and use statistical anonymization for research and quality-improvement use cases.
Implement technical safeguards
Effective healthcare data security solutions include encrypting data in transit and at rest (prefer customer-managed keys), enforcing granular role- and attribute-based access with MFA, and segmenting networks using Zero Trust (deny-by-default, least privilege, controlled egress). Gate all model calls through a policy proxy that enforces minimum-necessary scopes, applies redaction/tokenization, and blocks risky destinations. Automate comprehensive logging of every interaction—who called what, with which scopes and data sources, and what the model returned.
Ongoing oversight and auditing
Run scheduled risk assessments and internal audits, monitor prompts/outputs for potential PHI leaks with real-time alerts, and keep a human in the loop for any output that could affect care or billing. Track model/data lineage, evaluate drift and quality, and maintain incident playbooks (containment, rollback, re-evaluation). Train staff regularly on safe LLM use, escalation paths, and how to recognize and report leakage risks.
Privacy-preserving architecture
Apply the minimum-necessary principle to drive a metadata-only AI pattern where raw PHI remains in your secure stores and the model sees only governed semantics; capture comprehensive audit logs for every query and response (who, what, when, which scopes, which sources); and use statistical anonymization pipelines to support research and quality-improvement use cases without re-identification risk.
Automated data lifecycle management
Treat prompts, embeddings, retrieval artifacts, and logs as regulated data with configurable retention periods, enforce legal holds when required, and perform verifiable deletion across your own systems and all vendors/subprocessors so residual copies do not linger beyond policy.
Zero-trust architecture
Segment networks and services with deny-by-default and least-privilege access, require strong authentication and granular authorization on every call, continuously verify posture and context, and enforce egress controls through a policy proxy to secure health data exchange.
Need a partner to design and implement this safely?
healthcare AI solutions development services.Conclusion
LLMs deliver real gains in documentation, analysis, and patient experience when they operate within clear privacy boundaries. Effective deployments rely on a metadata-first design, isolated infrastructure for any PHI, and zero trust controls with full auditability.
A simple risk lens of access, egress, and impact clarifies model choices. PHI workloads align with isolated or custom models, while public models fit only non-PHI tasks with de-identification and policy controls, supported by governance consistent with HTI-1 and the EU AI Act.
Edenlab designs privacy-first AI architectures for healthcare, emphasizing isolated deployments, metadata-only patterns, and auditable controls aligned with HIPAA, HTI-1, and the EU AI Act. The team brings deep FHIR® and interoperability expertise to implement secure, scalable, HIPAA-compliant data integration workflows that translate governance requirements into day-to-day operations.

HIPAA-ready AI, from design to deployment
We architect secure, auditable LLM workflows that keep data inside your boundary and prove compliance.
FAQs
Is building a custom HIPAA-compliant LLM always better than buying?
Not always. Buy when the work is strictly non-PHI (e.g., literature summaries, internal policy drafts) or you need a fast pilot. Build (or use an isolated/custom deployment) when any identifier could enter prompts, outputs write back to clinical systems, or you need deep traceability and control.
How can Edenlab help audit an existing AI solution for HIPAA compliance?
We trace data flows, test controls (encryption, RBAC/ABAC with MFA, logging, egress), and run prompt-leak checks. You get a gap analysis across BAA/retention/“no-training” terms and HTI-1/EU AI Act posture, plus a prioritized remediation plan.
What business use cases are safe for LLMs under HIPAA?
Administrative FAQs, scheduling, literature summaries, and analytics on de-identified or aggregated data are typically safe. PHI-aware tasks can be safe on isolated infrastructure with minimum-necessary access and human-in-the-loop review.
If a vendor claims HIPAA compliance, what should we verify before signing?
Confirm a scoped BAA, “no training on your data,” data-residency, security controls, immutable logs, and clear TTLs with verifiable deletion. Ask for HTI-1 transparency readiness, EU AI Act obligations (if relevant), and current SOC 2/ISO 27001.
What happens if PHI leaks through prompts? Is my organization liable?
Generally, yes, the covered entity remains responsible (with shared responsibility per your BAA). Immediately contain, preserve logs, perform a Breach Notification Rule risk assessment, notify as required, and remediate.
Stay in touch
Subscribe to get insights from FHIR experts, new case studies, articles and announcements
Great!
Our team we’ll be glad to share our expertise with you via email





