
Healthcare organizations today face a critical interoperability imperative: many still rely on decades-old electronic health record (EHR) and electronic medical record (EMR) systems that were never designed for modern data exchange. In fact, 76% of healthcare organizations are using multiple clinical systems over ten years old for core operations.
Replacing these legacy EHRs outright is often impractical; the cost of a full rip-and-replace runs into millions of dollars and significant downtime. Instead, integrating legacy systems with contemporary standards is the pragmatic path to modernization.
HL7® FHIR® (Fast Healthcare Interoperability Resources) has emerged as the leading standard to bridge these gaps. FHIR defines a uniform RESTful API and standardized data models (“resources”) for health data, using modern web technologies (JSON, XML, HTTP).
Regulators are actively driving FHIR adoption: in the U.S., the 21st Century Cures Act Final Rule mandates that certified EHRs expose patient data via FHIR APIs, and in Europe, initiatives like the eHealth Digital Services Infrastructure (eHDS) and the European Interoperability Framework promote cross-border exchange using FHIR. These mandates make FHIR-based EHR integration not just an IT upgrade, but a compliance requirement.
In practice, that means making EHR FHIR and EMR FHIR connectivity practical, not just “FHIR-ready on paper,” but implemented in a way that supports real workflows, including FHIR prior authorization automation. This article focuses on FHIR EHR integration and EMR FHIR integration strategies that are realistic for brownfield environments, especially when the goal is bridging legacy EHR with FHIR without disrupting core clinical operations.
By leveraging FHIR for legacy EHR/EMR integration, healthcare organizations can modernize data sharing and unlock new capabilities without a full system transplant. A FHIR EHR integration layer allows legacy data to be accessed through standardized APIs, enabling everything from patient-facing mobile apps to analytics platforms to securely retrieve information. Many providers are embracing “FHIR-first” strategies—often with the help of specialized interoperability platforms (for example, Kodjin)—to accelerate these efforts and reduce integration complexity.

Below, we will outline key strategies and best practices to bridge legacy EHRs with HL7 FHIR in a way that is technically sound and aligned with business goals.
The Challenge of Proprietary Data Models and Non-Standard Formats
One of the first challenges in integrating FHIR into a legacy EHR system is dealing with the legacy’s proprietary data model and non-standard data formats—exactly the pain point that FHIR for legacy EHR and FHIR for legacy EMR initiatives run into early.
Older EHRs often store clinical data in unique schemas or archaic formats (e.g., custom relational databases, HL7 v2 messages, flat files) that do not map cleanly to FHIR’s standardized resources. Each vendor or system might use different coding systems and data definitions. These inconsistencies make FHIR for legacy EHR integration difficult because you can’t reliably translate legacy data into FHIR Patient, Observation, or MedicationRequest resources without careful mapping.
As a best practice, many organizations start with a thorough data inventory and gap analysis. It’s crucial to identify all key data elements in the legacy system and determine how each corresponds to FHIR resources and fields, especially when the target architecture is EHR integration with HL7 FHIR interfaces at enterprise scale.
Often, organizations will need to create a mapping dictionary or use middleware to transform non-standard fields into standard FHIR data. This is where FHIR integration for legacy EHR succeeds or fails: the mapping logic, terminology normalization, and update strategy must be treated like product engineering, not a one-off ETL script.
It’s also essential to assess the legacy system’s connectivity options at this stage. Determine what integration points the old system provides; are there any existing APIs, database read access, or even batch export capabilities? You may be surprised to find “hidden” hooks in older platforms that can be leveraged. Understanding the proprietary data model and available access points will shape the overall integration approach and the tooling needed.
Mapping FHIR for a legacy EHR requires careful planning: catalog the data, normalize formats, and chart out how to extract or receive updates from the old system. This groundwork sets the stage for the technical transformation in the next steps.
Data Transformation Approaches: Real-Time vs. Batch
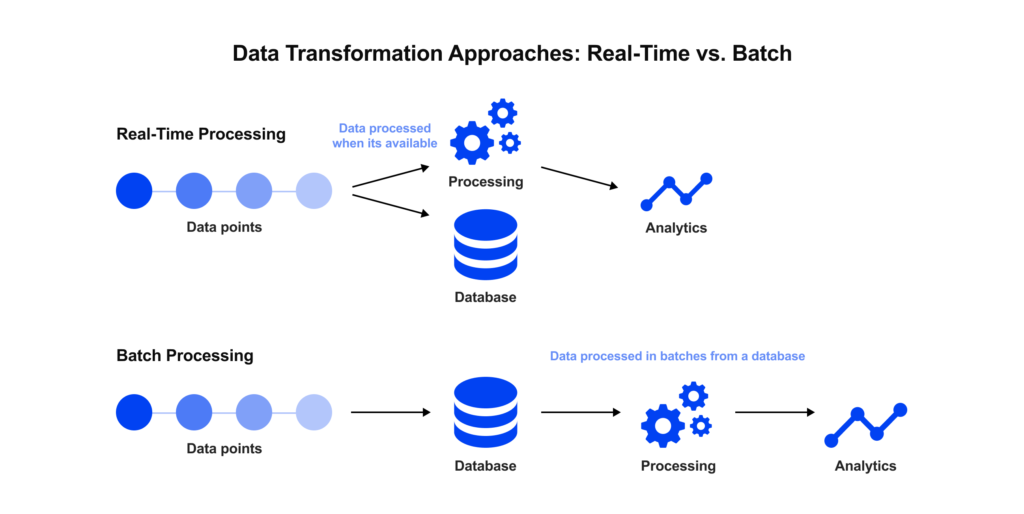
Once you understand the legacy data, the next challenge is transformation, converting that proprietary format into FHIR in a reliable way. For teams integrating FHIR into legacy EHR systems, there are two primary approaches to consider for data transformation: real-time (on-the-fly) conversion versus batch (asynchronous) conversion. Each has its role in an integration strategy, and in practice, a hybrid of both is common.
1. On-the-Fly (Real-Time) Transformation – In this model, a FHIR layer (for example, FHIR facade) sits in front of the legacy system and dynamically translates requests into the legacy’s format (and vice versa) in real time. When a client application calls the FHIR API (for example, asking for a Patient record), the system fetches the necessary data from the legacy database or API, transforms it on the fly into a FHIR Patient resource, and returns it to the caller.
This approach has several advantages. It provides up-to-the-minute data (always pulling the latest from the source) and does not require maintaining a separate data store. It’s also minimally disruptive to the old system: the facade is an add-on component that leaves the underlying database untouched, allowing the organization to incrementally modernize without a full overhaul.
However, real-time transformation can be complex to implement and performance-intensive. Every FHIR request triggers conversion logic, which may involve complex mappings or multiple legacy queries. If a single FHIR resource needs to aggregate data from several legacy tables or modules, the solution must handle that composition on demand.
Moreover, if the legacy system emits data in pieces (e.g., lab results first come as an order entry, then updated with results later), a pure real-time approach might have to hold state or delay responses until all pieces are available, which complicates the design.
Real-time facades are best suited when the data requests are relatively straightforward or when immediate freshness of data is critical. Many large EHR vendors (Epic, Cerner, etc.) have, in fact, adopted a real-time FHIR transformation model—they expose FHIR endpoints that translate to their internal system calls—but these often only support a subset of data or operations due to underlying limitations.
2. Batch (Asynchronous) Transformation – ETL: In a batch approach, legacy data is extracted and transformed in bulk on a scheduled or continuous basis, rather than upon each request. This often means setting up an ETL (Extract-Transform-Load) pipeline or using an integration engine that periodically pulls data (e.g., nightly dumps, event streams, or triggers on new entries) from the legacy system, converts it to FHIR, and then stores it in a target database (often a separate FHIR server or data repository).
Batch integration can also be near-real-time using message queues: for instance, legacy system events are published to a queue (using HL7 v2 messages, JSON messages, etc.), and a consumer service transforms each message to the corresponding FHIR resource and loads it into the FHIR data store. Tools like Apache Kafka or RabbitMQ are commonly used to enable this kind of streaming sync reliably.
The batch approach decouples the heavy lifting of transformation from user requests. Complex mapping logic can run behind the scenes without keeping a client waiting for a response. It also allows for assembling composite records: for example, you might accumulate all components of a patient visit over a few minutes and only create the FHIR Encounter resource when everything is complete, ensuring the FHIR representation is comprehensive.
This approach can improve performance for consumers, especially if combined with a FHIR repository (discussed in the next section), because clients query a ready-made FHIR dataset instead of hitting the old system each time. Batch processing is very useful for initial data migration, especially in projects involving EHR data migration services, and for integrating data that doesn’t change rapidly (e.g., demographics, historical notes).
The downside is that data may not be perfectly up-to-the-second; if the batch runs nightly, users see yesterday’s info. Mitigating this often involves increasing frequency or using a mix of real-time and batch: critical data changes can be pushed through event streams in seconds, while large volumes of less critical data sync on a schedule.
In practice, organizations often use a hybrid model. For instance, a project might do a one-time bulk migration of all patient records and past observations into a FHIR server, then enable a real-time feed for new or updated data going forward.
The decision on real-time vs. batch comes down to use case: if the integration is supporting point-of-care clinical apps, real-time freshness might be non-negotiable; if it’s for a research data warehouse or analytics, nightly or hourly updates could be acceptable. The key is to design the transformation pipeline such that it ensures data integrity (no pieces lost) and can handle updates.
Facade vs. Native Integration: Choosing the Right Architecture
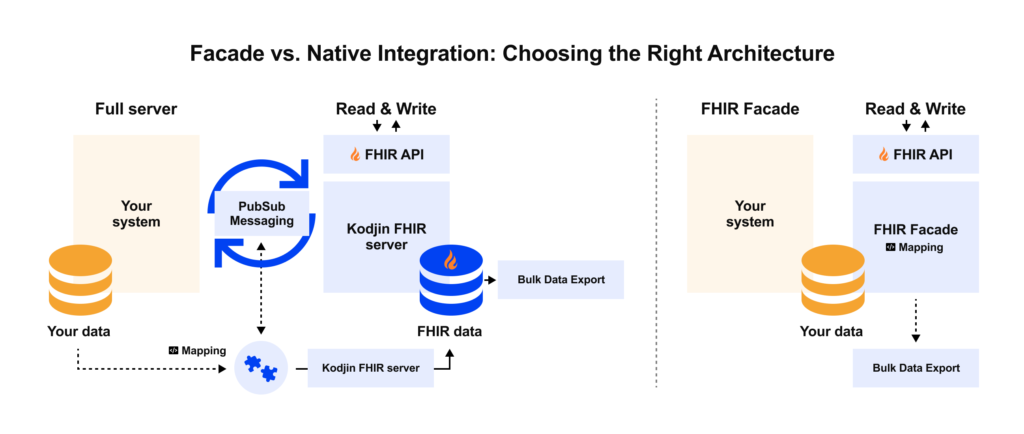
When planning FHIR integration, it’s important to clarify whether the goal is a facade or a path toward a native FHIR architecture, especially when you’re dealing with FHIR support for outdated EHRs where “just expose an API” can hide serious operational constraints.
A FHIR facade (interface layer) is often the fastest way to get results. As described, the facade translates between FHIR and the legacy’s proprietary format on the fly, acting as a translator.
The appeal here is clear: you avoid modifying the legacy system’s core. The facade can be developed and deployed independently, minimizing risk to the operational EHR. This approach is ideal for incremental modernization, where you deliver immediate interoperability (e.g., patient API access) without waiting for a massive overhaul.
Many organizations start here to satisfy pressing needs like regulatory compliance or an urgent integration deadline. A facade also allows you to test the waters of FHIR: you can learn what data is most requested, how the performance holds up, and where the legacy system’s limitations are, before investing further.
The downside of a pure facade approach is that you are effectively papering over an outdated core. The legacy data model and limitations still lurk beneath the surface. If the legacy system cannot easily support a certain use case, the facade cannot magically overcome that. A facade might meet basic FHIR integration requirements but could fall short for more demanding or innovative applications down the line.
A native FHIR integration implies moving the architecture such that FHIR is not just an overlay but part of the core data handling. This could mean the legacy vendor itself upgrades the product to internally use FHIR resource models, or, more practically, for a healthcare provider, that you implement a FHIR-based data store (repository) in parallel and gradually shift source-of-truth status to it (as discussed under data storage).
Over time, the goal might be that clinicians and upstream systems are interacting with the FHIR repository, with the legacy system quietly syncing in the background until it can be fully retired.
A fully “native” FHIR EHR would store and manage data as FHIR resources at the lowest level, eliminating translation needs entirely, but in reality, few existing EHRs have completely rebuilt their internal architecture to FHIR. Instead, most are using the facade model today. That said, forward-looking institutions are leveraging the facade as a stepping stone: while the facade runs, they invest in extracting all legacy data into a new FHIR-native database.
This can be done gradually (module by module or data domain by domain). For instance, an organization might first set up a FHIR repository for patient demographics and documents and link it to the old EHR. Next, they incorporate lab results into the repository, and so on, until the legacy system’s role diminishes.
The facade vs. native question can be framed by time horizon and capabilities needed. If you need a quick win and have a stable legacy system that you plan to keep for a while, a facade might be sufficient for now. If you are aiming for EHR modernization and possibly replacing the legacy system in a controlled manner, investing in a more native FHIR solution (with dual storage and eventual migration) is wise.
Often, the answer is a hybrid: use a facade to satisfy immediate integrations, but architect it in tandem with a FHIR repository that you populate in the background. This way, you get the best of both: minimal disruption now, with a path to a more robust FHIR-based infrastructure over time.
Need more than a one-off interface?
Discover how Edenlab’s healthcare interoperability consulting helps align legacy EHRs, HIEs, and partner systems around HL7 FHIR without disrupting clinical operations.
Healthcare Interoperability solution development pageData Storage Considerations (Single Source vs. Dual Storage)
A critical architectural decision in FHIR integration is whether to maintain a separate FHIR data store. In other words, will you store data in two places—the legacy database and a new FHIR repository—or solely in the legacy and translate on demand? This choice fundamentally affects the complexity, performance, and capabilities of the integrated solution.
On one hand, a pure facade approach (as described above) avoids duplicating data. The legacy system remains the single source of truth, and FHIR data is generated only when needed. This simplifies data governance (no need to sync two databases) but can limit functionality.
Many legacy EHRs were not built for the kind of querying FHIR enables; for example, a FHIR search for all patients with diabetes might be hard to serve with legacy indexes. Without a dedicated FHIR store, such queries must be translated into complex legacy queries (if possible at all) and will put a load on the old system.
On the other hand, implementing a FHIR repository means you store the data natively in FHIR format in a new database (for example, using a FHIR server platform or cloud health data service). This inevitably creates data redundancy; you now have legacy and FHIR data stores, but it brings important benefits.
A FHIR repository acts as a high-performance cache and integration hub: it can serve complex queries efficiently without touching the legacy system and can support features like full-text search or population-level data export (using FHIR’s Bulk Data API) that legacy systems usually cannot.
By managing data in FHIR format persistently, you eliminate the need for costly real-time conversions on each request and can ensure a consistent, enterprise-wide view of data. For example, if you need to run analytics or feed an AI algorithm, it’s much easier to pull from a consolidated FHIR database than from an outdated system’s tables or APIs.
Of course, maintaining two synchronized stores introduces challenges. You’ll need robust change capture and synchronization logic so that any new or updated record in the legacy system is promptly reflected in the FHIR store (and potentially vice versa if two-way updates are allowed).
This is where integration middleware or messaging feeds are useful; they can continuously update the FHIR repository in near real time as changes occur.
Despite the overhead, many organizations choose a dual-storage strategy because it decouples the legacy backend from new innovation. The legacy system can continue operating for core transaction processing, while all modern integrations (apps, data sharing, reporting) hit the FHIR layer. Over time, the FHIR repository can even evolve into the primary system of record as legacy components are phased out.
For many organizations, dual storage becomes the practical bridge to EHR modernization with FHIR APIs: the legacy system stays stable for transactions, while the FHIR layer becomes the integration and innovation surface area.
Exposing a FHIR API and Enabling SMART on FHIR
Whether using a facade, a repository, or both, the end result of FHIR enablement is to provide standard FHIR APIs to internal and external systems—most commonly by deploying a FHIR platform for EHR integration with FHIR server capabilities (search, validation, profiles, and consistent REST behavior).
At a basic level, implementing the FHIR API means deploying a FHIR server or integration layer that supports the HL7 FHIR RESTful interface (HTTP GET/POST/PUT/DELETE on resource endpoints). There are various ways to do this: you could use an open-source FHIR server (like HAPI FHIR) connected to your data, a cloud-based service, or a commercial solution.
The FHIR API should adhere to the FHIR specification for resource formats and behaviors so that any application that knows FHIR can interact with it. Ensuring conformance to core profiles (discussed more in the next section) will make your API truly interoperable and not just FHIR in name.
Just as important as data format is the security and authorization framework. Healthcare data is sensitive, so your FHIR API must be protected with industry-standard authentication. The widely adopted approach is to implement a SMART on FHIR framework: a profile of OAuth2 and OpenID Connect tailored to healthcare. SMART on FHIR enables third-party apps to request specific scopes of data access and ensures that the user (patient or clinician) grants permission.
In practice, this means your legacy EHR integration should include an OAuth2 authorization server or leverage one from an EHR platform so that apps connecting to the FHIR API go through proper auth flows (e.g., the patient logs in and approves an app to read their data).
In practice, this is how a SMART on FHIR-enabled EHR ecosystem is secured: standardized authorization flows, scoped access, and auditable controls that match clinical reality. By enforcing SMART on FHIR’s OAuth2 standards, you mitigate the risk of exposing data to unauthorized parties.
Additionally, you should implement role-based access control (RBAC) rules on the data; for instance, only clinicians can access certain write operations, or a patient app can only see that one patient’s record. These controls, combined with encryption (TLS) on all connections, help maintain security and privacy in the new API layer.
Security and Compliance as Non-Negotiable
We touched on SMART on FHIR and OAuth2 for securing the API. In addition, enforce strong encryption (TLS for data in transit and encryption at rest for any databases or message queues storing PHI). Implement role-based access controls for internal users/integrations, principle of least privilege, and multi-factor authentication for any admin access.
Also, be mindful of compliance frameworks: HIPAA in the U.S. and GDPR in Europe both require careful handling of patient data. For example, GDPR would necessitate that patients (data subjects) have certain rights to their data; your FHIR API should facilitate fulfilling those (like providing an electronic copy of records).
Information blocking regulations in the U.S. mean you must make sure the FHIR API isn’t unjustly withholding data (once you claim to provide it). Ensuring continuous compliance means building these considerations into your design from the start, not as afterthoughts. A secure, compliant integration engenders trust and avoids costly breaches or penalties down the line.
Workflow Integration and Change Management
An often overlooked aspect is how new FHIR-based capabilities fit into existing workflows for clinicians and staff. Engaging end-users early can prevent developing an integration that technically works but isn’t adopted.
For example, if a FHIR app is introduced for clinicians, provide single sign-on so they aren’t juggling extra logins (integrating with your enterprise SSO or OAuth provider). Ensure that context sharing is enabled, e.g., launching a SMART on FHIR app with a patient’s context, so the user doesn’t have to search for the patient again in the new app. These little workflow touches make a big difference in usability. Plan for training super-users and champions on the new tools; these folks can help colleagues adapt to any new interfaces or processes.
From an IT perspective, integrate the support process: your helpdesk and support teams should be trained to understand the new FHIR integration components so they can troubleshoot issues effectively (often integration issues span across systems and require coordinated debugging).
Vendor and Talent Management
Recognize the human factor in this project. If your team lacks FHIR expertise, invest in training or bring in experienced interoperability consultants. There is a learning curve with FHIR (understanding resources, profiles, etc.) and legacy HL7 standards, so ensure your project staff is up to the task.
Alternatively, low-code integration tools or hiring a vendor specialized in FHIR integration can accelerate progress if internal resources are limited. When working with external partners (vendors or consultants), clearly define deliverables around compliance and performance to avoid a partial solution.
If your legacy EHR vendor is involved, hold them accountable for providing data access or the technical info needed; sometimes, establishing a partnership or support agreement with the vendor is necessary so that the integration doesn’t break support terms.
Implementing these best practices creates a more robust integration infrastructure. Your goal is not just to set up a one-off interface, but to establish a sustainable ecosystem where your legacy EHR can continue to operate and evolve in tandem with new technology.
Interoperability is an ongoing journey, and standards evolve (FHIR will have newer versions; new implementation guides will emerge), and your integration must adapt. By leveraging solid architecture, securing everything, engaging users, and planning for scale, you set your organization up to reap the benefits of FHIR integration for the long haul.
Conclusion
Integrating FHIR into legacy EHR systems enables healthcare organizations to modernize on their own terms, preserving the value of existing systems while meeting today’s interoperability demands. By addressing proprietary data challenges, implementing smart transformation pipelines, and adhering to standards, even outdated EHRs can be made to speak FHIR.
The result is a more connected healthcare environment: patients gain easier access to their data, providers can deploy innovative apps and analytics, and the organization stays compliant with emerging regulations. Perhaps most importantly, a well-executed FHIR integration provides a foundation for future healthcare IT innovation; it’s a stepping stone toward an API-driven ecosystem where data flows securely and seamlessly to wherever it’s needed.
Legacy EHR integration is undeniably complex, but with the strategies outlined—from FHIR facades to native repositories and from terminology mapping to secure API management—it is achievable in a predictable, stepwise fashion. Each legacy environment will require a tailored blend of these approaches.
The guiding principle is clear: use FHIR not just as a technical standard, but as an enabler of business goals (better care coordination, new digital services, competitive advantage in data exchange). With careful planning and the right expertise, organizations can bridge the old and the new, creating a future-ready health IT landscape that leverages the best of both legacy reliability and FHIR-enabled innovation. Bridging legacy EHRs with FHIR is more than a checkbox for compliance; it’s a strategic investment in the agility and longevity of your healthcare IT.

Ready to make your legacy EHR speak FHIR?
Talk to Edenlab’s interoperability team about a step-by-step integration roadmap: from FHIR facades and ETL pipelines to secure SMART on FHIR APIs and a future-proof data architecture.
FAQs
Can legacy EHRs be upgraded to support FHIR without vendor changes?
Yes, in many cases, legacy EHRs can expose FHIR without changing the core vendor system by adding an external FHIR layer: you extract data via existing interfaces (DB views, HL7 v2, CSV, APIs), normalize it in an integration layer, and publish it through a dedicated FHIR server or gateway.
This approach leaves the legacy EHR untouched while enabling modern, standards-based APIs for analytics, interoperability, or third-party apps.
How long does FHIR integration usually take?
Timelines vary widely by scope and data quality, but a focused pilot that exposes a handful of resources (e.g., Patient, Encounter, Observation) typically takes from a few weeks to a few months, while full-scale, enterprise-wide integration (multiple systems, dozens of resources, governance, and production hardening) usually runs from several months to over a year.
The biggest drivers are data complexity, the number of source systems, regulatory constraints, and how quickly SMEs can make decisions on mappings and business rules.
Which FHIR modules are easiest to start with?
Most organizations start with administrative and core clinical resources that are well-defined and present in almost every EHR: Patient, Practitioner, Organization, Encounter/Visit, and basic clinical facts such as Observation (labs, vitals) and Condition (diagnoses).
These resources map to existing data structures more directly, are frequently needed for analytics and interoperability, and create a solid foundation for later expansion into medications, procedures, care plans, and more advanced workflows.
What if our data isn’t structured enough for mapping?
If your data is poorly structured or buried in free text, the first step is to stabilize ingestion and cleaning: standardize identifiers, normalize codes where possible, and separate obviously structured fields (dates, numeric values, codes) from pure narrative.
For unstructured content, you can either start with simpler use cases that only rely on structured fields or gradually introduce NLP/AI or manual abstraction to extract key data elements; in parallel, you should update upstream processes so that new data is captured in a more structured, FHIR-friendly way going forward.
Does Edenlab provide integration testing or sandbox environments?
Yes, Edenlab typically provides FHIR server sandboxes and test environments so teams can try integrations safely before going to production. These environments are used to validate mappings, run sample workloads, test performance, and verify interoperability with your existing systems or partner applications, helping de-risk the rollout and shorten the path from prototype to live deployment.
Stay in touch
Subscribe to get insights from FHIR experts, new case studies, articles and announcements
Great!
Our team we’ll be glad to share our expertise with you via email







