
Public health data repositories are large-scale health information systems that centralize critical healthcare data at the national or regional level. These repositories include systems like centralized clinical data repositories, ePrescription and eDispensation platforms, insurance claims and coverage databases, as well as public health reporting databases (for example, systems for COVID-19 case surveillance or antimicrobial resistance tracking).
They are designed to be used by a broad range of stakeholders—healthcare professionals, general practitioners, insurance companies, pharmacies, and laboratories, to share and access health data across an entire country or region.
Unlike local hospital databases, national public health information systems have a much wider impact on patients and providers. For example, Ukraine’s eHealth platform is a nationwide system built on modern standards (HL7 FHIR) that now serves over 36 million patients.
These platforms often adopt health data standards such as HL7 Clinical Document Architecture (CDA) and HL7 v3, and some are transitioning into early versions of HL7 FHIR for better interoperability. However, data validation for data quality in public health systems is frequently handled with custom-built rules rather than systematic, standards-based validation tools. This means that even if data nominally follows a standard format, many errors or inconsistencies can slip through due to fragmented or specific validation approaches.
Why Public Health Data Often Fails
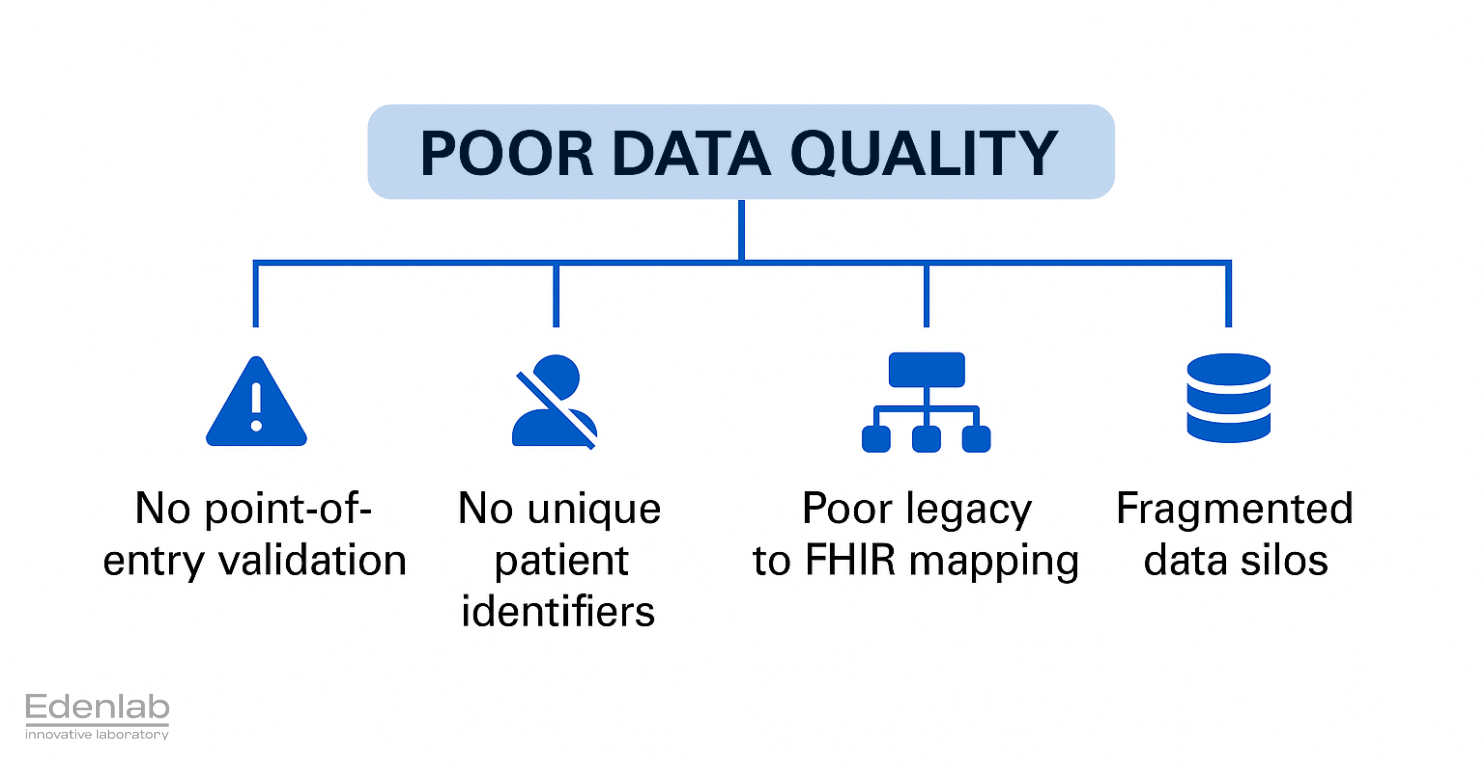
Ensuring high data quality in public health repositories is not just a technical challenge; it’s a systemic one involving workflow, health data governance, and design. Several root causes contribute to public health data quality issues in these systems:
- Lack of point-of-entry validation: Many national health systems still rely on manual data entry without robust validation at the source. This means data can be entered in free text or inconsistent formats without checks. Without immediate validation, errors go unnoticed, yet “point-of-entry validation routinely checks if data are reasonable, complete, consistent, and formatted in accordance with system requirements.” When such validation is absent, typos, missing fields, and format inconsistencies proliferate.
- Absence of unique patient identifiers across systems: Incomplete patient identification is a major cause of duplicate and mismatched records. If each system uses its own patient IDs or none at all, it becomes difficult to link records referring to the same person. Introducing a universal patient identifier is known to significantly reduce the occurrence of duplicate medical records since a unique code can link patient information accurately across various systems.
So, without a common identifier, different databases cannot easily reconcile whether “John A. Smith” in one repository is the same person as “Jonathan Smith” in another, resulting in duplicate or incomplete patient records.
- Poor data model mapping during modernization: As countries modernize legacy health IT systems to newer standards like FHIR, often the mapping of old data fields to new structures is imperfect. If the legacy-to-FHIR data mapping is not carefully done, critical information may be dropped or misclassified.
Proper mapping ensures seamless integration of disparate EHR systems and efficient data exchange, giving a unified view of patient data that improves care coordination. But if this process is rushed or lacks expertise, the new system may inherit bad data or misalignments from the old, perpetuating healthcare data quality challenges even in a modern platform.
- Fragmented data silos: In many public health domains, data is collected in separate, siloed systems—think of standalone registries for specific diseases (HIV, tuberculosis, cancer) or specialized reporting tools that aren’t integrated with the main electronic health infrastructure. These disease-specific or program-specific databases often use different formats and operate in isolation. As a result, information remains fragmented and cannot easily be aggregated or cross-referenced unless a robust healthcare integration solution is in place.
One study on patient registries with various data sources in public health research noted that such systems are frequently developed as closed data silos with incompatible formats and no common standards, which poses a barrier to linking patient-centric electronic records across registries. In practice, this means a patient’s data for one program (e.g., a COVID-19 lab result in a surveillance database) might never get linked to their records in another (like the national EHR or vaccination registry), undermining the completeness and public health data accuracy.
These root causes lead to serious consequences:
- Inaccurate or delayed public health reporting: When data comes in with errors or gaps, national statistics and surveillance reports become unreliable. For example, inconsistent case data during a pandemic can delay outbreak detection or misallocate resources.
- Broken surveillance workflows: Public health workflows (like disease notification or antibiotic resistance tracking) can break down if the underlying data is incomplete or out-of-date. Missing lab results or unlinked records mean health authorities don’t get the full picture, leading to missed trends or slow responses.
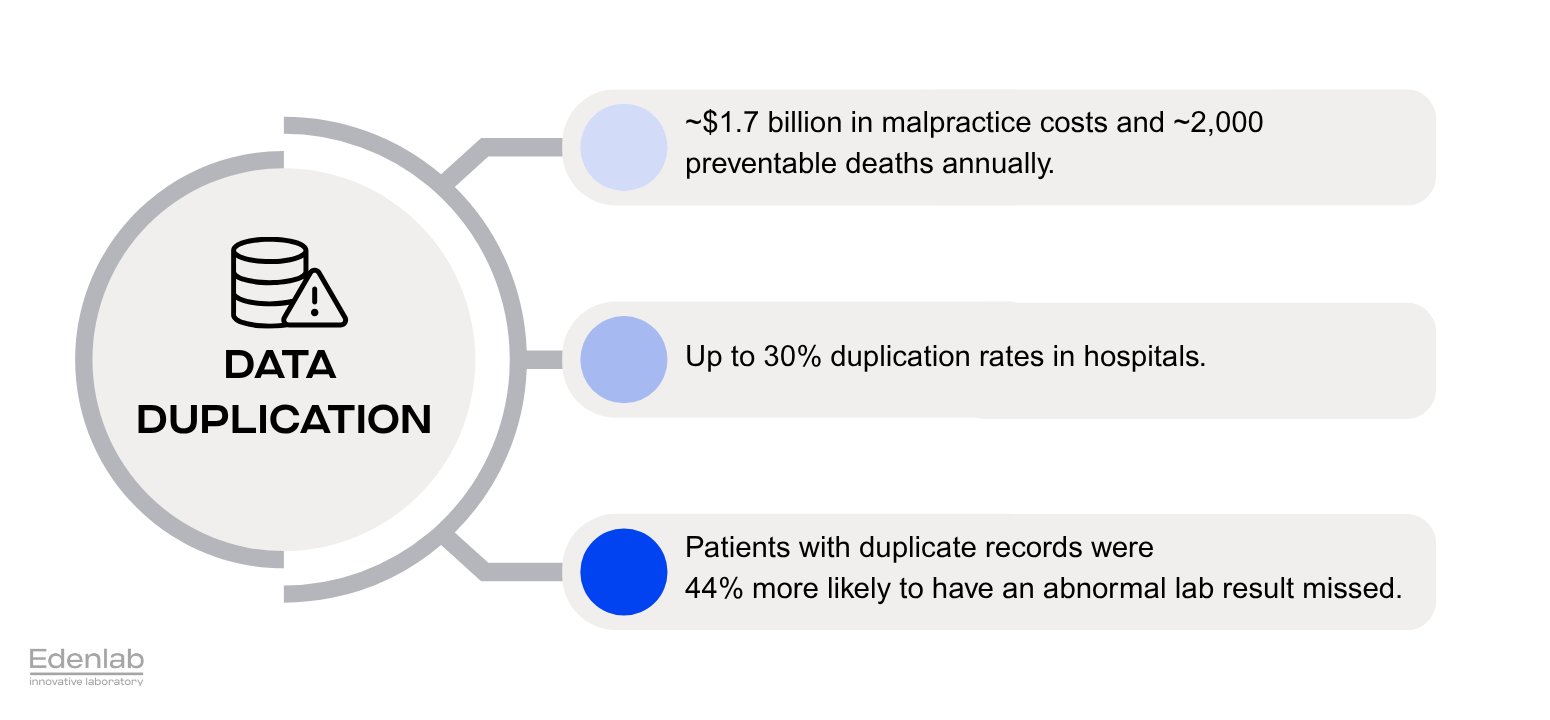
- Duplicated or incomplete patient records: Patients often end up with multiple records scattered across systems. Duplicates compromise care; if a clinician only sees one fragment of a patient’s data, they might miss critical history. Studies have found that duplication is rampant.
Duplication rates are as high as 30% in some healthcare organizations, and a 10% rate is common. Up to half of patient records are not matched in transfers between healthcare systems. This fragmentation endangers patients by causing errors like medication conflicts or redundant procedures.
- Failed coordination between services: Poor data quality in healthcare also disrupts how different health services connect. For instance, if an ePrescription system isn’t properly linked to the insurance claims system (due to inconsistent patient or prescription identifiers), a pharmacy might dispense medication that the insurer fails to recognize for reimbursement. Identification errors have financial fallout: one survey estimated that 33% of denied insurance claims were due to inaccurate patient identification or information. This not only causes revenue loss but also administrative headaches and delays in patient care.
To address these issues effectively, public health authorities need not just technical fixes like FHIR normalization or deduplication logic, but also holistic healthcare data analytics services that combine domain expertise, standardized data pipelines, and continuous monitoring to transform raw data into trusted insights.
In summary, dirty data in these repositories undermines every level of healthcare decision-making.
“Without clean, standardized input, even the best analytics can’t deliver reliable health insights.”
Health IT leaders must recognize that no amount of fancy analytics or AI can compensate for fundamentally poor health data integrity. The good news is that this is a solvable problem.
Key Strategies to Improve Data Quality
Public health data improvement in terms of quality requires technical fixes and process changes.

Here are key strategies that can make a significant difference.
FHIR normalization
When healthcare organizations move toward a single data standard, such as HL7 FHIR, they lay the groundwork for true interoperability. With FHIR, the structure of health data becomes harmonized, so information coming from different software systems can finally speak the same language. Even older or proprietary formats can be transformed into FHIR as needed, either by wrapping existing records or translating them in real time. This consistency streamlines data exchange, makes information more trustworthy, and keeps it easier to work with.
The advantages do not stop at having a shared format. One major strength of FHIR is that it checks and validates incoming information the moment it arrives, which helps keep errors out from the start. It is flexible, too: organizations can validate data against multiple rule sets (profiles) inside the same installation, so one system can handle different requirements for departments, regions, or use cases without extra solutions.
FHIR’s API is also notably robust. Advanced search features let users filter and locate exactly the records they need, even across huge datasets. The standard supports both real-time streaming requests and larger scheduled batch transfers, so it can serve daily clinical operations as well as big-picture analytics and research projects.
Just as important, FHIR makes secure, standards-based public health data sharing possible. Through frameworks like SMART on FHIR, trusted agencies can connect to provider systems, apply their own filters, and retrieve the precise information they need quickly and in a consistent, reliable format. This supports timely, accurate public health reporting and ongoing monitoring.
Choosing FHIR as the data backbone not only solves today’s interoperability challenges but also prepares healthcare organizations for a future in which clean, validated, and easily accessible information drives better care and smarter health policy.
Validation at the point of data entry
The earlier you catch errors, the better. Implement strict validation rules in user interfaces and data entry forms used by clinicians, pharmacists, and staff. Electronic forms should enforce standardized codes (for diagnoses, drugs, etc.), required fields, and format checks (like dates in the correct format). Point-of-service systems (tools and software used directly at the location where care is delivered or a service is provided) can use dropdown menus, data type checks, and real-time validation services so that invalid entries are rejected or flagged immediately.
This proactive approach aligns with healthcare data quality management best practices, where point-of-entry validation checks that data is reasonable, complete, and properly formatted as it is recorded. Such front-line validation dramatically reduces downstream cleanup by preventing bad data from ever entering the repository.
Deduplication logic and unified patient records
To tackle duplicates and fragmentation, introduce robust deduplication processes powered by unique identifiers and smart matching algorithms. Ideally, implement a national unique patient identifier to unequivocally link records across all systems.
If you lack a single ID, use an enterprise master patient index (EMPI) solution to match records via demographic and other data. Modern EMPI and master data management tools can automatically match and manage patient records to reduce the occurrence of duplicate records.
Metadata structures, such as global patient IDs, record linkage IDs, or even biometric identifiers, should be embedded so that whenever a new record is created or updated, the system checks if that person already exists in the database. By merging duplicate entries and filling in missing links, healthcare data quality solutions ensure each patient has one complete record rather than scattered bits of information.
Real-time monitoring for anomalous data detection
It’s crucial to continuously monitor data quality, not just fix it once. Implement real-time analytics or dashboards that track data quality in healthcare metrics, such as missing values, out-of-range entries, duplicate records, or interface failures, across the repository.
Public health authorities and system administrators should be able to see, for instance, if a particular hospital is submitting an unusually high number of voided records or if a lab’s data feed suddenly drops in volume (indicating a potential interface problem).
Interactive dashboards have been used effectively by organizations like the CDC; for example, the National Notifiable Diseases Surveillance System (NNDSS) now uses interactive dashboards to monitor public health data quality issues, helping teams “identify and resolve problems quickly and ensure data accuracy.” By catching anomalies early (through automated alerts or visible indicators on a dashboard), data stewards can intervene to correct issues before they propagate. This kind of continuous quality oversight creates a culture of proactive healthcare data quality management and continuous improvement.
Implementing these strategies often requires expertise in healthcare interoperability and system integration. At Edenlab, we developed extensive experience in these areas—from FHIR normalization to building validation and integration tools—through our projects. FHIR ensures consistency across datasets, making data reusable, interoperable, and ready for real-time public health data improvement.
Conclusion
Clean, high-quality data is the lifeblood of effective healthcare decisions. When public health data repositories have reliable data, officials can make faster decisions in a crisis, clinicians get a complete view of their patients, and analysts can derive insights that truly reflect reality. The improvements are tangible: high-quality data allows healthcare providers to make more accurate diagnoses, offer more effective treatments, and avoid dangerous errors. In other words, better data translates directly to better patient outcomes and safer, more efficient public health information systems.
For large-scale health IT environments, investing in data quality in public health means investing in the nation’s health. It enables confident, real-time public health surveillance (no more waiting weeks for cleaned spreadsheets) and builds public trust that health data integrity is maintained. Moreover, a solid data foundation sets the stage for advanced innovations like AI-driven analytics or nationwide health information exchange—you can’t successfully deploy those on top of faulty data.
Edenlab’s value in this domain lies in our deep expertise in secure architecture design, analytics-ready infrastructure, and leadership in HL7 FHIR interoperability. Our team has helped build one of the world’s largest FHIR-based eHealth systems (serving over 36 million users) from the ground, and we continue to lead in implementing solutions that ensure data quality and interoperability from day one. We understand that technology is only part of the equation—good governance, user-friendly workflows, and iterative testing are all pieces of the puzzle to fix public health data quality issues at the root.
The bottom line is when you turn your healthcare data into a trustworthy asset; it becomes an engine for better care and smarter policy. High data quality empowers stakeholders at every level, from hospital administrators to health ministry officials, to act with confidence and speed.

We dive deep where others skim
Our healthcare software development firm brings the expertise and precision needed to tackle the industry complexities. With a specialized focus on healthcare processes, regulations, and technology, we deliver solutions that address the toughest challenges.
FAQs
How can I tell if our public health system has a serious data quality problem?
Look for signs like high duplicate rates, mismatched records, inconsistent reports, or delays in public health surveillance and analytics.
We know our data is messy; where should we even start fixing it?
Start with a baseline data quality assessment and implement validation at the point of data entry. Focus on one high-impact registry or workflow first.
Is it possible to improve data quality without rebuilding everything from scratch?
Yes. Tools like FHIR wrappers, validation services, and EMPI systems can clean and harmonize existing data without a full replacement.
Can we keep things compliant (like GDPR or HIPAA) while working on data validation and cleanup?
Yes. Compliance is achievable through access controls, encryption, audit logs, and ensuring no personal data is processed beyond its intended use.
What should we look for in a vendor or tech partner for this kind of project?
Look for deep FHIR expertise, experience with national-scale health data systems, and a proven track record in validation, interoperability, and governance.
Can FHIR really help clean up and connect legacy data sources?
Yes. FHIR can wrap or transform legacy data formats, apply validation rules, and expose data via APIs for consistent, real-time access.
Stay in touch
Subscribe to get insights from FHIR experts, new case studies, articles and announcements
Great!
Our team we’ll be glad to share our expertise with you via email








